
Introducing Renoir, ChipAgents' First Model

A new fine-tuned model is bringing frontier-level AI performance to chip design at a fraction of the cost and entirely within customer-controlled infrastructure
Today, we are excited to introduce Renoir, an agentic large language model (LLM) whose name means "renew." Renoir is designed to renew what semiconductor teams can expect from AI: greater performance, lower costs, and secure on-premises deployment.
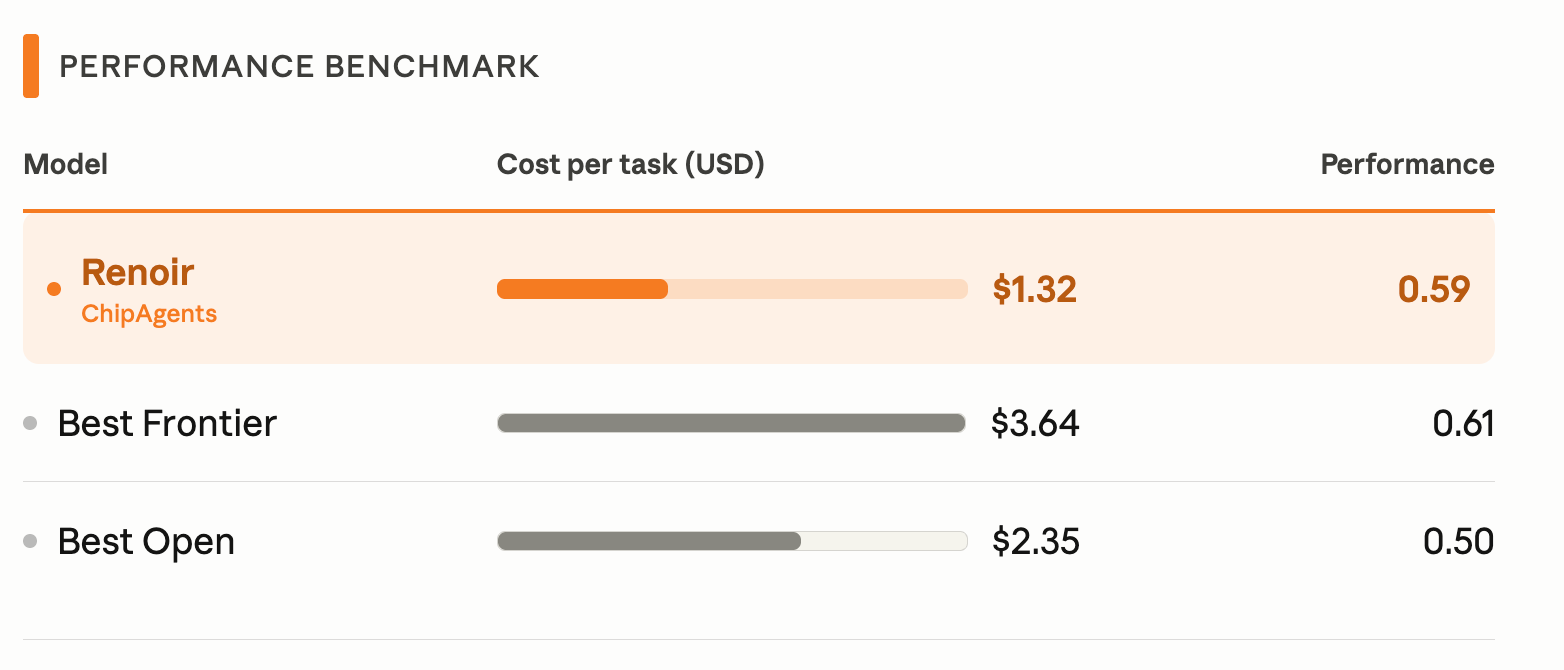
In early chip design benchmarks, Renoir outperforms the base model it was trained on, approaches the performance of Claude Opus 4.6, and cuts costs by more than half. Furthermore, it can run entirely on-premises, allowing semiconductor companies to develop faster without compromising on their strict security requirements.
Why Train Our Own Model?
In our experience with existing models—both closed and open—for semiconductor design workflows, we have found three critical limitations to address with Renoir:
Data Scarcity
Public data is limited. Unlike domains such as software engineering, the vast majority of valuable knowledge in the semiconductor industry lives within companies' walled gardens. By training Renoir with our internal data curation methods, we enable agents to become more widely adopted in hardware design.
On-Premises Security Requirements
For many semiconductor companies, design files, proprietary intellectual property, and internal debugging logs are too sensitive to be sent to third-party cloud environments. Renoir enables AI models to run in an air-gapped, on-premises environment. Now, teams can fully own their deployment, data, and security policies.
Local Inference Without Dependency
Teams using Renoir can work without accessing external APIs, saving latency and per-token billing costs compared to third-party clouds. While token costs for frontier models may drastically change over time, Renoir's operating costs are more predictable.
How did we train our own model?
Renoir was fine-tuned based on an open-weight, mixture-of-experts large language model (MoE LLM) with a carefully curated mix of public semiconductor data and proprietary data created as part of ChipAgents' training stack.
- Data Curation: We used a mixture of manual and automated methods to collect hardware repositories, technical documentation, and open-source hardware designs.
- Data Synthesis: We developed automatic task-generation pipelines to turn these data sources into high-priority chip design scenarios. While doing so, we placed special emphasis on examples that reflect the scale and complexity of real-world engineering problems. Our proprietary data mixture targets topics including RTL generation, specification understanding, debugging, test generation, tool-use, etc.
- Fine-tuning: We then fine-tuned our base model on a large multi-node GPU cluster, running dozens of experiments to select an optimal dataset composition and training configuration.
Results
Renoir approaches Claude Opus 4.6 on our internal chip design benchmark suite, which covers RTL generation, bug localization, and natural language specification-to-code implementation. Compared to Claude Opus 4.6, Renoir is Pareto-optimal on the cost-performance frontier.
The current model was trained with a constrained budget of data, time, and compute. It should therefore be considered an audition. With larger datasets and longer training runs on deck in the ChipAgents research team, we expect performance to continue climbing.
The Road Ahead
With Renoir, chip design teams that were previously unable to use LLM-based agents due to IP protection requirements now have a credible on-prem option that offers frontier-grade intelligence at a fraction of the cost.
We are actively collaborating with our partners to train bespoke models on their data. By entering, training in, and remaining within their walled gardens, Renoir will soon become the semiconductor industry's defining frontier agent model.
If you are interested in deploying Renoir on your premises, please reach out to kexun@alphadesign.ai.
Frequently Asked Questions
What does "approaches Claude Opus 4.6" mean precisely?
It means ChipAgents scores within a defined margin of Opus 4.6 on our internal chip design benchmark suite, which covers RTL generation, bug localization, and specification-to-code translation. It does not mean it matches Opus 4.6 on general-purpose benchmarks. Domain specificity is the point: the model is optimized for chip design tasks, not general reasoning.
Will you train models with customer data? Will customer design data be used only for their own model training?
Any use of customer data for model customization or performance improvement is governed by the customer's data handling agreement and explicit approval. When permitted, customer data can be used to improve model performance for that specific customer's deployment. Customer design data is isolated and will not be used to train models for other customers.